최근 오브젝트 디텍션의 yolo 모델이 다시한번 업그레이드 되었다!
YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
git :https://github.com/WongKinYiu/yolov7

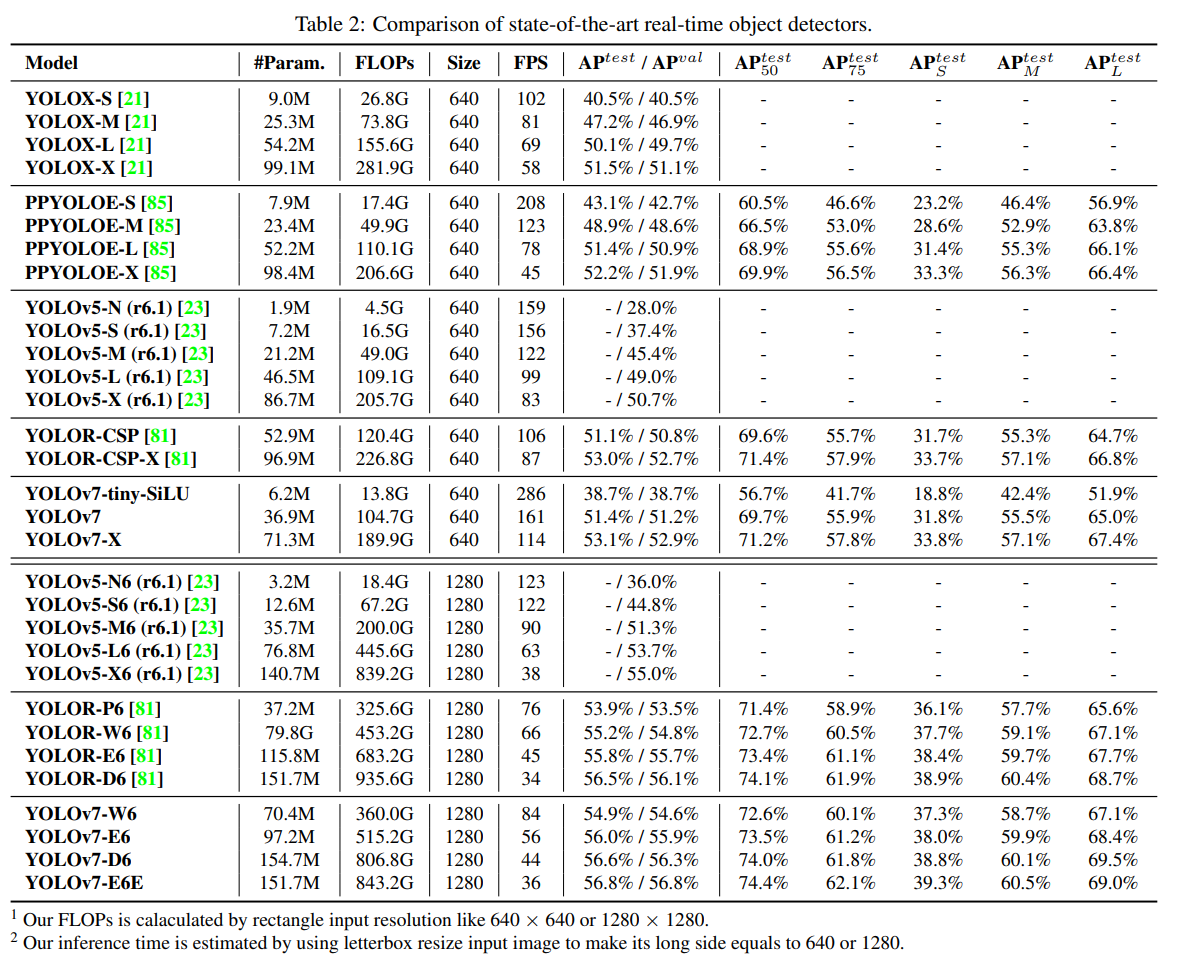
그림과 같이 COCO벤치마크 실험에 따르면 Swin, ConvNeXt 보다 좋은 성능을 보이고 있으며, 심지어 FLOps 도 104.7G 로, YOLOv4 (142.8) 보다 15% 줄였다.
이 외에도, 본 논문이 기여한 것은 다음과 같다.
1) Trainable bag-of-freebies : 모델을 더 좋게 학습시키는 여러 방법들
2) Object detection 에서 다음 두가지의 어려움이 되는점을 다루는 방법을 제안한다
+ how re-parameterized module replaces original module
+ how dynamic label assignment strategy deals with assignment to different output layers
3) 효과적으로 파라미터 연산, 활용 할 수 있는 "extend", "compund scaling"
어떻게 더 빠르고 정확한 모델이 어떻게 나올 수 있었을까? 그 비법에 대해 알아보자.
Extended efficient layer aggregation networks
특징의 카디널리티*와, 가용 채널을 늘리기위해 기존의 ELAN 에서 group convolution을 이용했다. 병합 과정에서도 서로 다른 특징 그룹을 셔플 후 머지하는 방식을 사용.
* 카디널리티(Cardinality) 는 특징으로 부터 유추할수 있는 유효한 값의 수
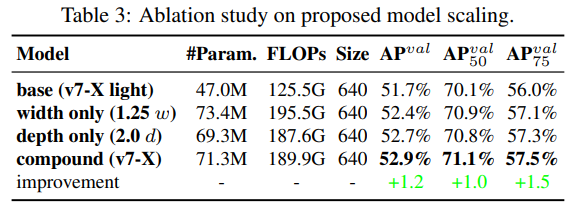
Model scaling for concatenation-based models
깊이를 증가시키면, transition layer의 입력과 출력 채널간의 비율 변화를 야기하기 때문에 모델의 하드웨어 사용을 저해한다. 그렇기때문에, concat-based model 을 위한 model scaling의 경우 그에 상응하는 복합된 스케일 기법이 필요로 하다. 본 논문에서는 다음과 같은 방식으로 Model scaling 을 적용했다. 이 방식은 초기 모델의 속성을 그대로 가지며, 그 최적 구조를 지닌다.
Trainable bag-of-freebies
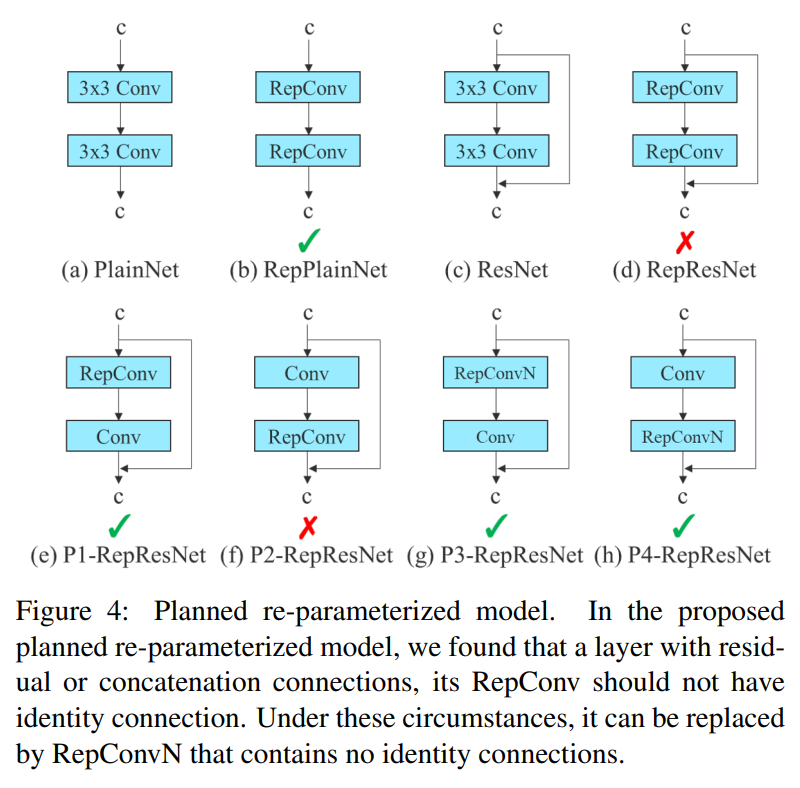
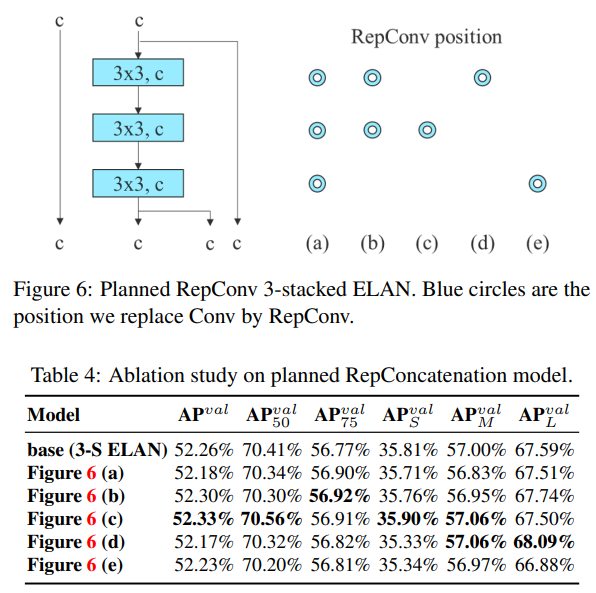
Planned re-parameterized convolution
우선 그림의 RepConv layer는 3x3 conv와 1x1 conv 의 결합이다. 실험 결과, RepConv 가 residual + concat 으로 얻어지는 서로 다른 피쳐맵의 더 diversity한 gradients 값의 생성을 저해하는것을 발견했다고 한다.
Coarse for auxiliary and fine for lead loss
Deep supervision 은 학습시 추가적인 Auxiliary head 의 shallow한 네트워크 가중치와 assistant loss 를 가이드삼는 기술이다.
이 기술을 통해 모델 퍼포먼스를 효과적으로 향상 시킬 수 있다.
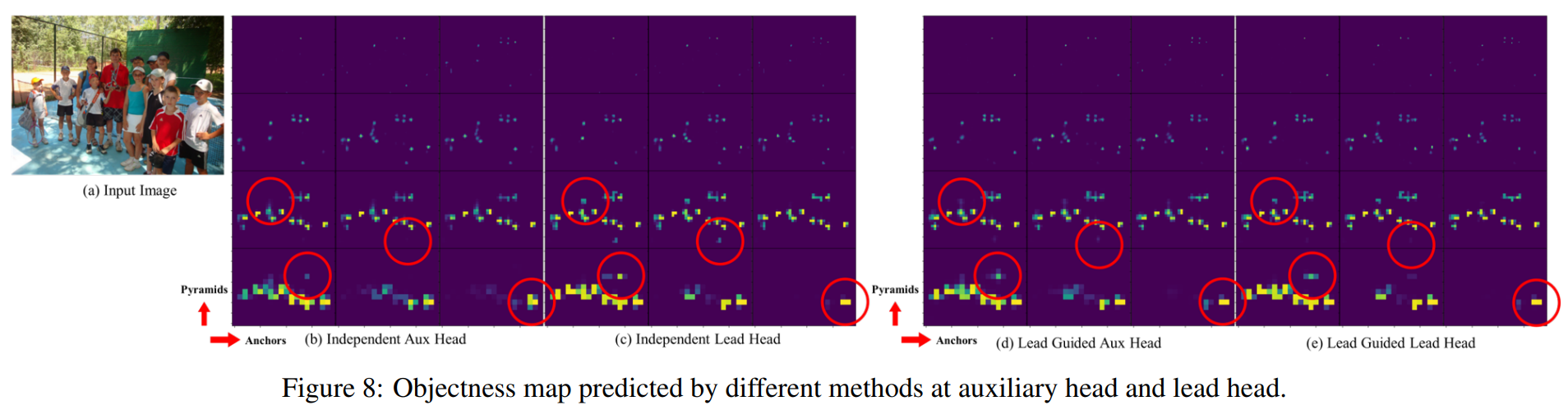
본 논문에서는 이를 따라 최종 출력에 관여하는 Lead Head 와 이를 보조하는 Aux Head 를 구현하며, 추가적으로 Lead head가 모델이 GT와 soft label(lead head output) 을 함께 고려하도록 가이드한다. 이때, Lead Head의 결과가 Assigner에 관여하여 정제된 Hierarchical labels (coarse label, fine label)를 생성하도록 하였다. 이렇게 한 이유는, Lead Head가 가이드하는 부분이 크므로 더 강한 학습 능력을 가지고있고, 소스와 GT간의 상관관계를 더 잘 표현 해줘야하기 때문. 일종의 residual learning 과 같다.
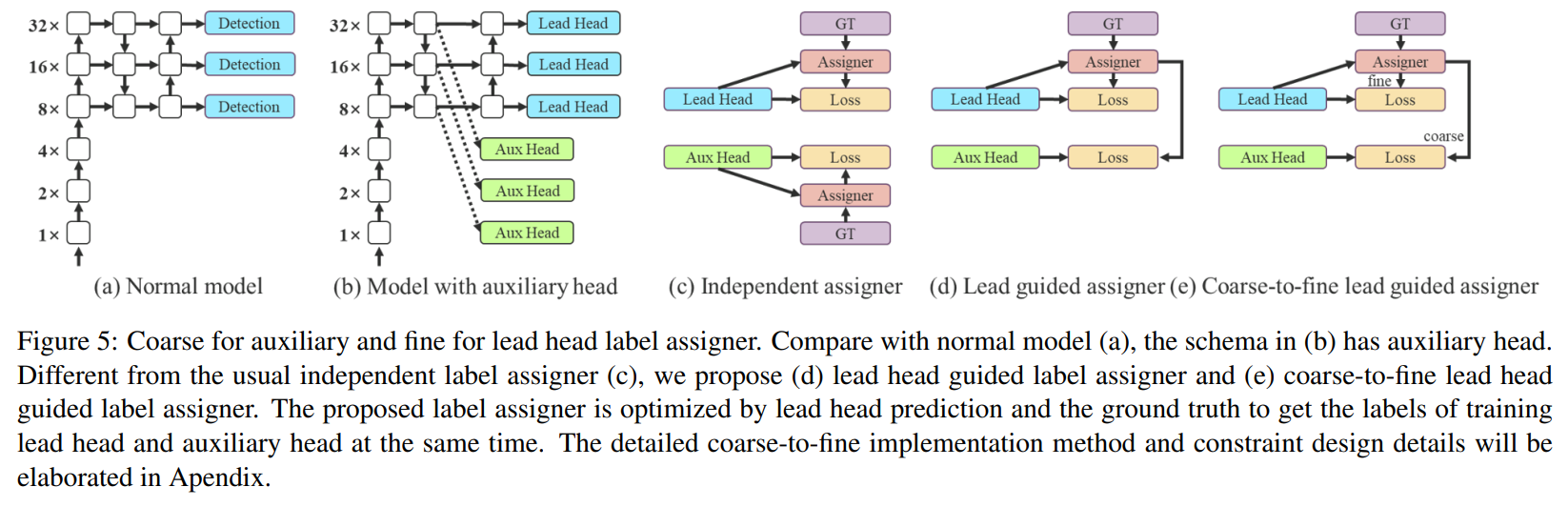
Hierarchical labels (coarse label, fine label)
- 높은 recall 결과로부터 발생된 높은 precision 결과들을 최종 아웃풋에서 필터할 수 있게 하였다.
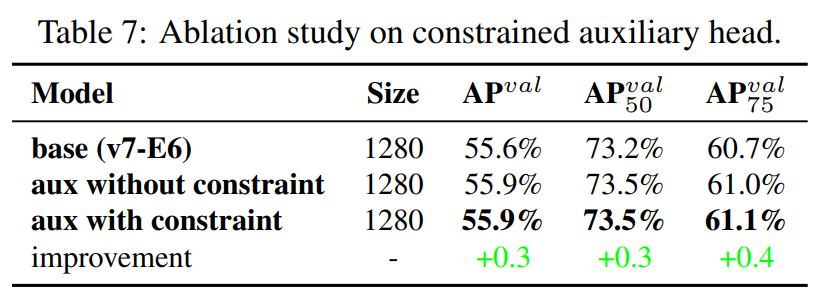
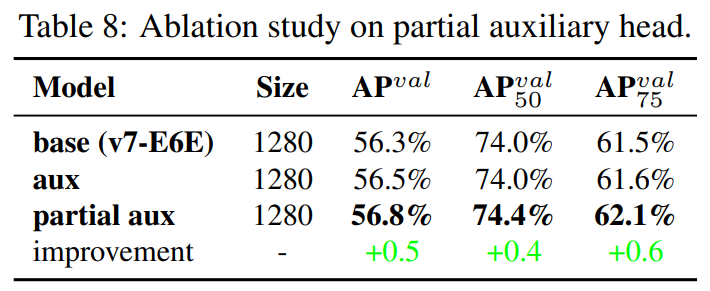
Other trainable bag-of-freebies
본 논문이 제안한 방법들 말고도 추가적인 freebies를 소개한다.
(1) Batch normalization in conv-bn-activation topology
(2) Implicit knowledge in YOLOR combined with convolution feature map in addition and multiplication manner
(3) EMA model:
Experiments
'Projects > 논문리뷰' 카테고리의 다른 글
| [논문리뷰] Attention-based Deep Multiple Instance Learning (1) | 2022.12.22 |
|---|